Data pipeline
Input: target web URL (the edited video)
Processing:
- Request metadata from an external source (e.g. Internet Archive)
Data parsing
- source locations (e.g. URLs)
- time (start and end of source, start and end of target URL)
- other extra information (filmed by, title etc.)
- captions metadata
Generate a manifest file - Have an chimera HLS/Dash manifest file (.m3u8 or .mpd) from the data, such that your playlist contains the metadata for segments and the rendering is prioritised. JWPlayer supports embedding manifest files https://support.jwplayer.com/customer/en/portal/articles/1430240-adaptive-streaming
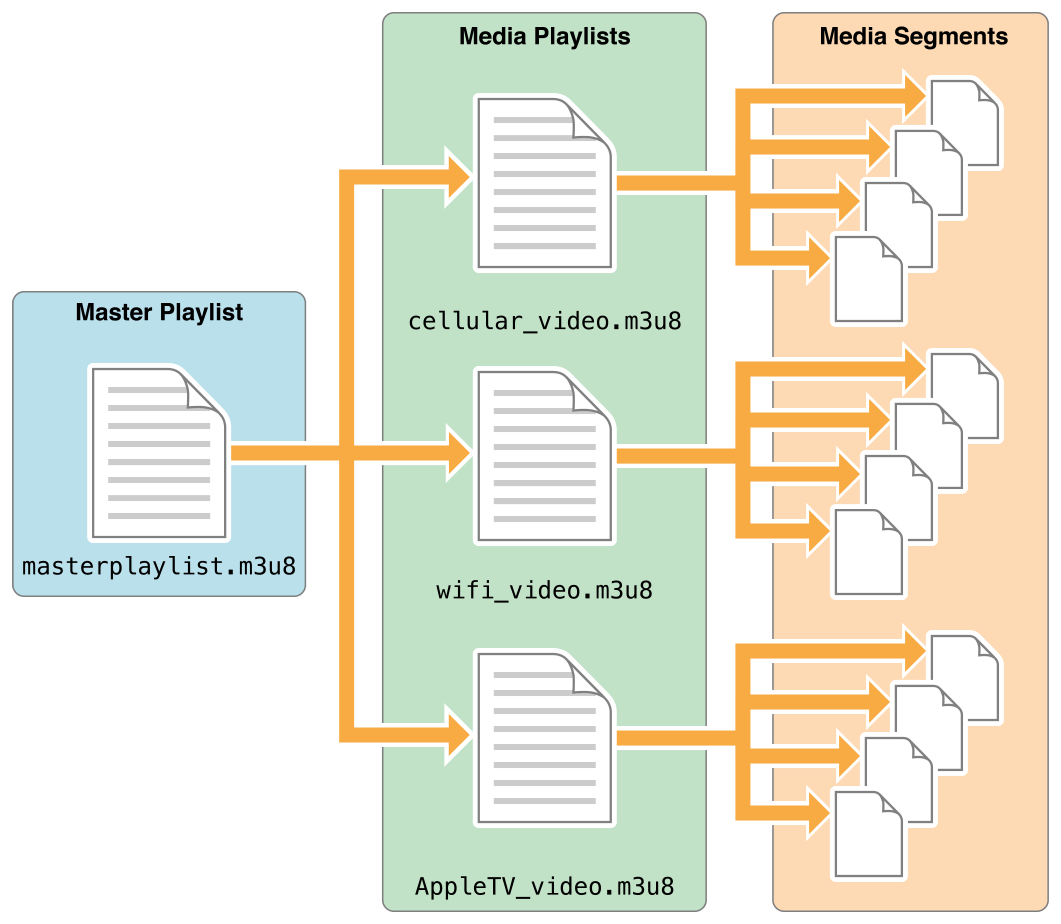 Example: https://bitdash-a.akamaihd.net/content/sintel/hls/playlist.m3u8
Note: It was pointed out the exact segment difficult to extract out exactly, but this is just a nice-to-have feature so the segments can be matched up with best effort.
Example: https://bitdash-a.akamaihd.net/content/sintel/hls/playlist.m3u8
Note: It was pointed out the exact segment difficult to extract out exactly, but this is just a nice-to-have feature so the segments can be matched up with best effort.
- Output:
- Captions
- Make the captions go the right way... (Top to bottom)
- Video
- Render a poorer quality video for the source file as well. Just because the video is a lot smaller.
- Pop up video frame that would be easier to close / be able to toggle between the top and bottom video.
- What happens when.. fade? Overlapping video? Silent?
- Captions
Data model
Data model will change based on the API endpoint of the database we get our information from. For now we have a mock manifest placed in the repository.
"id": "http://example.org/sample_video.json",
"type": "Manifest",
"label": "ABC NY Local News Segment on Trump Exclusive Interview",
"description": "This is a description of the ABC Local news segment.",
"sequences": {
"type": "Sequence",
"canvases": [
{
"id": "http://example.org/sample_video/canvas/1",
"duration": 132,
"content": [
{
"id": "http://example.org/sample_video/content/page/1",
"type": "AnnotationPage",
"items": [
{
"id": "http://example.org/sample_video/content/anno/1",
"type": "Annotation",
"motivation": "painting",
"body": {
"id": "http://example.org/media/abc_local_interview.mp4",
"type": "Video",
"format": "video/mp4"
},
"target": "http://example.org/sample_video/canvas/1#t=0,35"
},
{
"id": "http://example.org/sample_video/content/anno/2",
"type": "Annotation",
"motivation": "annotation",
"body": {
"id": "http://example.org/media/trump_interview.mp4",
"type": "Video",
"format": "video/mp4"
},
"target": "http://example.org/sample_video/canvas/1#t=36,62"
},
{
"id": "http://example.org/sample_video/content/anno/3",
"type": "Annotation",
"motivation": "painting",
"body": {
"id": "http://example.org/media/abc_local_interview.mp4",
"type": "Video",
"format": "video/mp4"
},
"target": "http://example.org/sample_video/canvas/1#t=63,77"
},
{
"id": "http://example.org/sample_video/content/anno/4",
"type": "Annotation",
"motivation": "annotation",
"body": {
"id": "http://example.org/media/trump_interview.mp4",
"type": "Video",
"format": "video/mp4"
},
"target": "http://example.org/sample_video/canvas/1#t=78,122"
},
{
"id": "http://example.org/sample_video/content/anno/5",
"type": "Annotation",
"motivation": "painting",
"body": {
"id": "http://example.org/media/abc_local_interview.mp4",
"type": "Video",
"format": "video/mp4"
},
"target": "http://example.org/sample_video/canvas/1#t=123,132"
},
]
}
]
}
]
}
}
See .m3u8 / mpd
Users needs
Not considered as this is the mock of a mock of a mock.